SAKURUG TECHBLOG



はじめに
こんにちは、Kotaです。
今回はEC2で立ち上げたLinuxの設定で、ユーザーの認証設定を誤り、デフォルトユーザー(ec2-user)やrootユーザーでログインできなくなった状況に対処するための手法をご紹介します。
おそらくこの記事をご覧になられているのは、インフラ業務を専門としていない方やAWS運用に慣れてない方が多いかと思います。
僕自身も正にそうで、実際に今回のタイトルのような状況に陥ってしまいました。解決方法を調べてみると、事例とその対処法が解説されている記事がいくつかヒットするのですが、もう少し詳細な手順を解説してくれている記事があったらなあと感じたため、今回は当事者でもある僕が対処法を解説できたらと思います。
なお、今回の記事はあくまで手順の解説に留めるので、単語の意味やコマンドの詳細については各リンクからご確認していただけるとより理解が深まるかと思います。
環境構築手順
まずは、実際にログインできない状況を再現していきます。
①【ログイン不可用(authError)】と【対処用(authRecovery)】のインスタンスを立ち上げます。
ここでの留意点として、2つのインスタンスのAZは統一しておきましょう。
異なるAZだと、この後のボリューム操作が出来ないためです。
②【authError】にログインし、sshdの設定を変更→反映します(コンソール)。
$ sudo nano /etc/ssh/sshd_config
変更内容
#PubkeyAuthentication yes → PubkeyAuthentication no
PasswordAuthentication no → PasswordAuthentication yes
$ sudo systemctl restart sshd.service
$ exit
ここではLinuxへのログイン方法を公開鍵認証からパスワード認証に変更しています。
デフォルトだとrootとec2-userにパスワードは設定されていないため、これでログインが不可能になります。
③【authError】サーバーにログインできないことを確認します。

ここまでで準備は完了です。
※ログインできなくなった原因を特定できていることを前提としています。
※ログインできない原因にはいくつかパターンがありますが、今回は例としてsshd_configでの認証設定ミスによるもので再現します。
対処手順
※以降では、一つ前の手順内容が反映されるのを待ってから次の手順に移ってください。
①【authError】インスタンスを停止します。
②ボリュームの設定画面から、【authError】のボリュームをデタッチします。
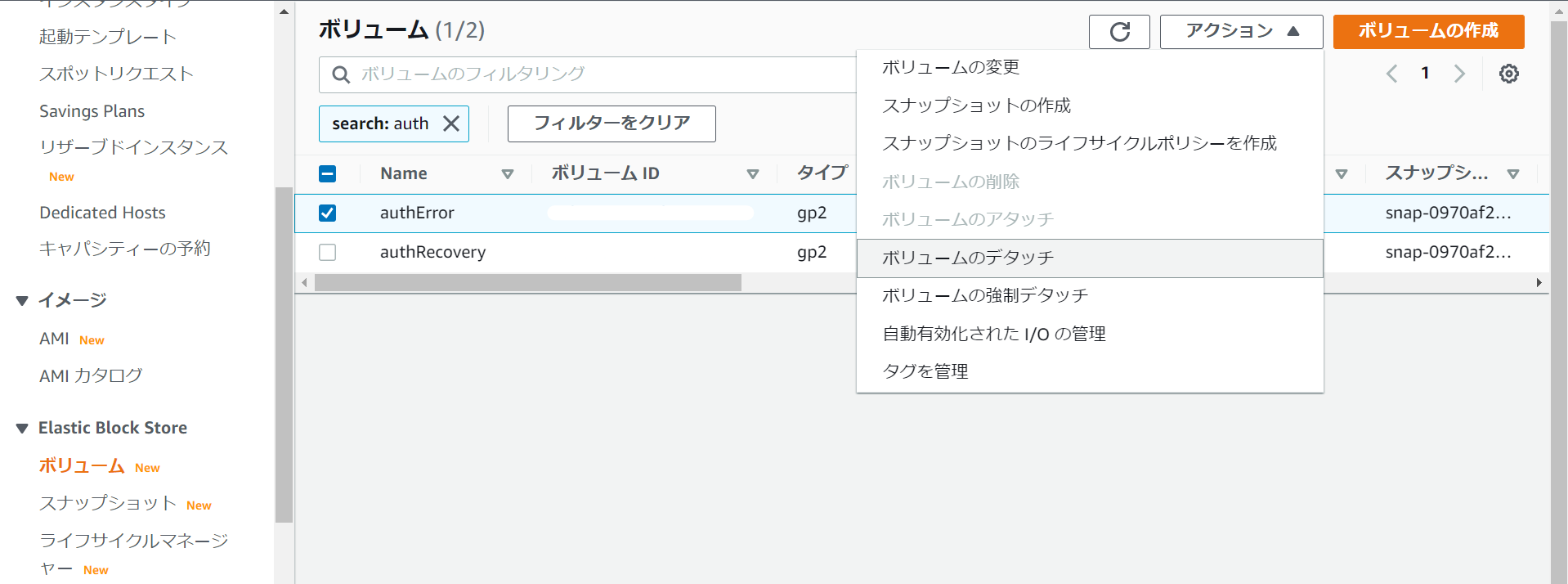
③【authError】のボリュームに【authRecovery】のボリュームをアタッチします。
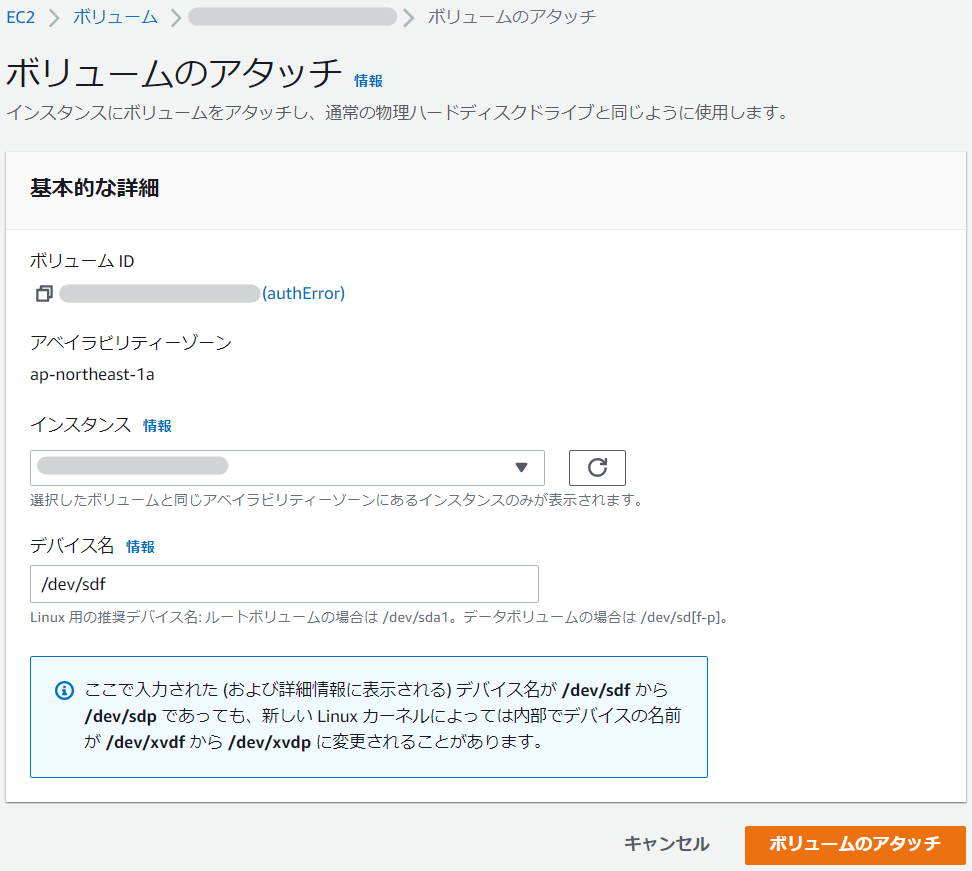
デバイス名はデフォルトのものを使用します。
④【authRecovery】インスタンスにログインし、【authError】のボリュームをマウントします。
・ディスクの状態を確認します。
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
└ xvda1 202:1 0 8G 0 part /
xvdf 202:80 0 8G 0 disk
└ xvdf1 202:81 0 8G 0 part
・マウントポイントを作成します。
$ sudo mkdir /mnt/recovery
・【authError】のボリュームをマウントします
$ sudo mount -t xfs -o nouuid /dev/xvdf1 /mnt/recovery
・マウント出来ているか確認します
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
└ xvda1 202:1 0 8G 0 part /
xvdf 202:80 0 8G 0 disk
└ xvdf1 202:81 0 8G 0 part /mnt/recovery
⑤ ④でマウントした【authError】のsshdの設定変更→反映を行います。
$ sudo nano /mnt/recovery/etc/ssh/sshd_config
変更内容
PubkeyAuthentication no → #PubkeyAuthentication yes
PasswordAuthentication yes → PasswordAuthentication no
$ sudo systemctl restart sshd.service
⑥ ④でマウントした【authError】のボリュームをアンマウント → ログアウトします。
・アンマウントの実行。
$ sudo umount -d /mnt/recovery
・アンマウントできていることを確認します。
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
└ xvda1 202:1 0 8G 0 part /
xvdf 202:80 0 8G 0 disk
└ xvdf1 202:81 0 8G 0 part
⑦再度【authError】のボリュームをデタッチします(②と同じです)。
⑧【authError】に元の【authError】ボリュームをアタッチします
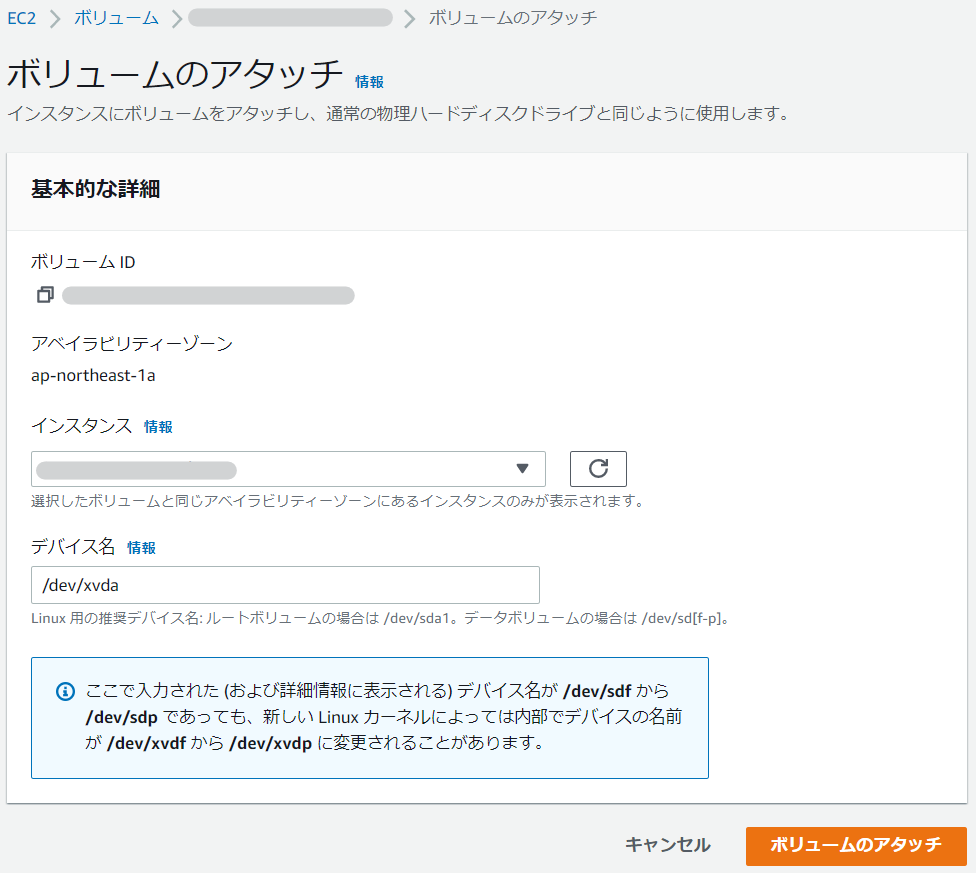
ここでの補足としては、デバイス名をsdaではなくxvdaとしている点です。
デバイス名はAMIの仮想化タイプによって異なります。
⑨【authError】インスタンスを再起動し、ログインできることを確認します。
まとめと学び
EC2で立ち上げたLinuxサーバーにログインできなくなったときの対処手順を解説しました。
権限やsshdの設定を誤ると影響範囲が大きく、また、対処に慣れていないと時間のロスでしかありません。
こちらの記事でもご紹介されているように、権限や接続設定を変更するときは
- 事前確認を徹底する
- 念のためssh接続を残した状態で変更内容を反映させる
ということを意識する必要があります。
サーバーの構築や運用って、慣れていない立場からすると怖い部分がありますよね、、、本番環境なら尚更です。こうした苦手意識の払拭や今回のような失敗を減らせるよう、サーバー運用についてもっと勉強する必要性を感じました。
今後もこのような失敗経験は本blogで積極的にアウトプットしていきます。
ではまた次回!
▼カジュアル面談実施中!
カジュアル面談では、会社の雰囲気や仕事内容についてざっくばらんにお話ししています。
履歴書は不要、服装自由、原則オンラインです。興味を持っていただけた方は、
ぜひ以下からお申し込みください。
皆さんにお会いできることをサクラグメンバー一同、心より楽しみにしております!
カジュアル面談応募フォームABOUT ME
