SAKURUG TECHBLOG



自己紹介
はじめまして、2024年10月に入社した、Keitaと申します。
これまで、主に社内向け営業支援システムの運用保守、統合顧客システムの開発などを行ってきました。
本題
自己紹介もこんなものにして、今回の本題について入ります。
今回の本題はApache BeamのFlink並列度はどのレベルなのかです。
公式ドキュメントを確認しても「並列度の設定」、のみの記載で結局どの範囲に適用されるのかが分からず、同じように困っている人がいたらと思い今回、記事作成にいたりました。
まずはApache Beam・Apache Flinkそれぞれの概要と、Apache Flinkの並列度について解説します。
Apache Beamとは
バッチ処理・ストリーム処理などのデータ処理を定義するフレームワークの1つです。
パイプライン作成や実行、変換などの処理を行うためのパイプラインを定義するための、
プログラムを構築するために利用されます。
ここからはBeamと呼称します。
Apache Flinkとは
バッチ処理・ストリーム処理を分散して処理できる、プラットフォームの1つです。
高パフォーマンス・低レイテンシを実現してたり、障害時に自動復旧可能など、耐障害性も高いツールです。
ここからはFlinkと呼称します。
Flinkの並列度について
今回の話をするにあたり、Flinkの並列度にはいくつかのレベルがある事をご理解ください。
・Operator Level
最も小さい単位で、各演算子のレベルでの設定。
・Client Level
2番目に小さい単位で、1つのジョブに対しての設定。
・Execution Environment Level
3番目に小さい単位で、その環境上すべてのジョブの並列度の設定。
・System Level
4番目に小さい単位で、すべての実行環境に対する設定。
検証
ソフトウェア | バージョン |
|---|---|
Apache Beam | 2.46.0 |
Apache Flink | 1.14.0 |
Java | 11 |
検証として以下のsetParallelism(1)とsetParallelism(2)つまり、並列度を1と2に設定したもので実行し、Flink Web Dashboardより並列度を確認します。
・並列度1のコード
package test;
import org.apache.beam.runners.flink.FlinkPipelineOptions;
import org.apache.beam.runners.flink.FlinkRunner;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.GenerateSequence;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.Filter;
import org.apache.beam.sdk.transforms.MapElements;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.transforms.SimpleFunction;
import org.apache.beam.sdk.values.PCollection;
import org.joda.time.Duration;
public class Test {
public static void main(String[] args) {
FlinkPipelineOptions options = PipelineOptionsFactory.create().as(FlinkPipelineOptions.class);
options.setRunner(FlinkRunner.class);
options.setParallelism(1);
options.setJobName("TestJob");
options.setFlinkMaster("172.18.12.61:8081");
Pipeline pipeline = Pipeline.create(options);
// データ生成
PCollection<Long> sequence = pipeline
.apply(GenerateSequence.from(0).withRate(1, Duration.millis(10000)));
// Map演算子を適用
PCollection<Long> mapped = sequence.apply(MapElements.via(new SimpleFunction<Long, Long>() {
@Override
public Long apply(Long input) {
return input * 2;
}
}));
// Filter演算子を適用
PCollection<Long> filtered = mapped.apply(Filter.by((Long input) -> input % 2 == 0));
// 非同期処理ステージ
PCollection<Long> asyncProcessed = filtered.apply(ParDo.of(new AsyncDoFn()));
// 処理内容を出力
asyncProcessed.apply(ParDo.of(new TestDoFn()));
// Flinkジョブを実行し、完了を待つ
try {
pipeline.run().waitUntilFinish();
} catch (Exception e) {
e.printStackTrace();
}
}
}・並列度2のコード
package test;
import org.apache.beam.runners.flink.FlinkPipelineOptions;
import org.apache.beam.runners.flink.FlinkRunner;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.GenerateSequence;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.Filter;
import org.apache.beam.sdk.transforms.MapElements;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.transforms.SimpleFunction;
import org.apache.beam.sdk.values.PCollection;
import org.joda.time.Duration;
public class Test2 {
public static void main(String[] args) {
FlinkPipelineOptions options = PipelineOptionsFactory.create().as(FlinkPipelineOptions.class);
options.setRunner(FlinkRunner.class);
//ここで並列度を2に設定
options.setParallelism(2);
options.setJobName("TestJob");
options.setFlinkMaster("172.18.12.61:8081");
Pipeline pipeline = Pipeline.create(options);
// データ生成
PCollection<Long> sequence = pipeline
.apply(GenerateSequence.from(0).withRate(1, Duration.millis(10000)));
// Map演算子を適用
PCollection<Long> mapped = sequence.apply(MapElements.via(new SimpleFunction<Long, Long>() {
@Override
public Long apply(Long input) {
return input * 2;
}
}));
// Filter演算子を適用
PCollection<Long> filtered = mapped.apply(Filter.by((Long input) -> input % 2 == 0));
// 非同期処理ステージ
PCollection<Long> asyncProcessed = filtered.apply(ParDo.of(new AsyncDoFn()));
// 処理内容を出力
asyncProcessed.apply(ParDo.of(new TestDoFn()));
// Flinkジョブを実行し、完了を待つ
try {
pipeline.run().waitUntilFinish();
} catch (Exception e) {
e.printStackTrace();
}
}
}またOperator Levelを確認するため、下記2クラスも追加しています。
package test;
import org.apache.beam.sdk.transforms.DoFn;
public class TestDoFn extends DoFn<Long, Void> {
@ProcessElement
public void processElement(ProcessContext ctx) {
System.out.println("Processed: " + ctx.element());
}
}package test;
import org.apache.beam.sdk.transforms.DoFn;
public class AsyncDoFn extends DoFn<Long, Long> {
@ProcessElement
public void processElement(ProcessContext context) {
Long input = context.element();
// 非同期呼び出しや処理をシミュレート
Long output = asyncOperation(input);
context.output(output);
}
private Long asyncOperation(Long input) {
// 非同期操作のロジックをここに記述
// 例えば、HTTPリクエストを行ったり外部サービスにアクセスしたりする
// 今回の本質ではないのでそのまま返す
return input;
}
}実行結果
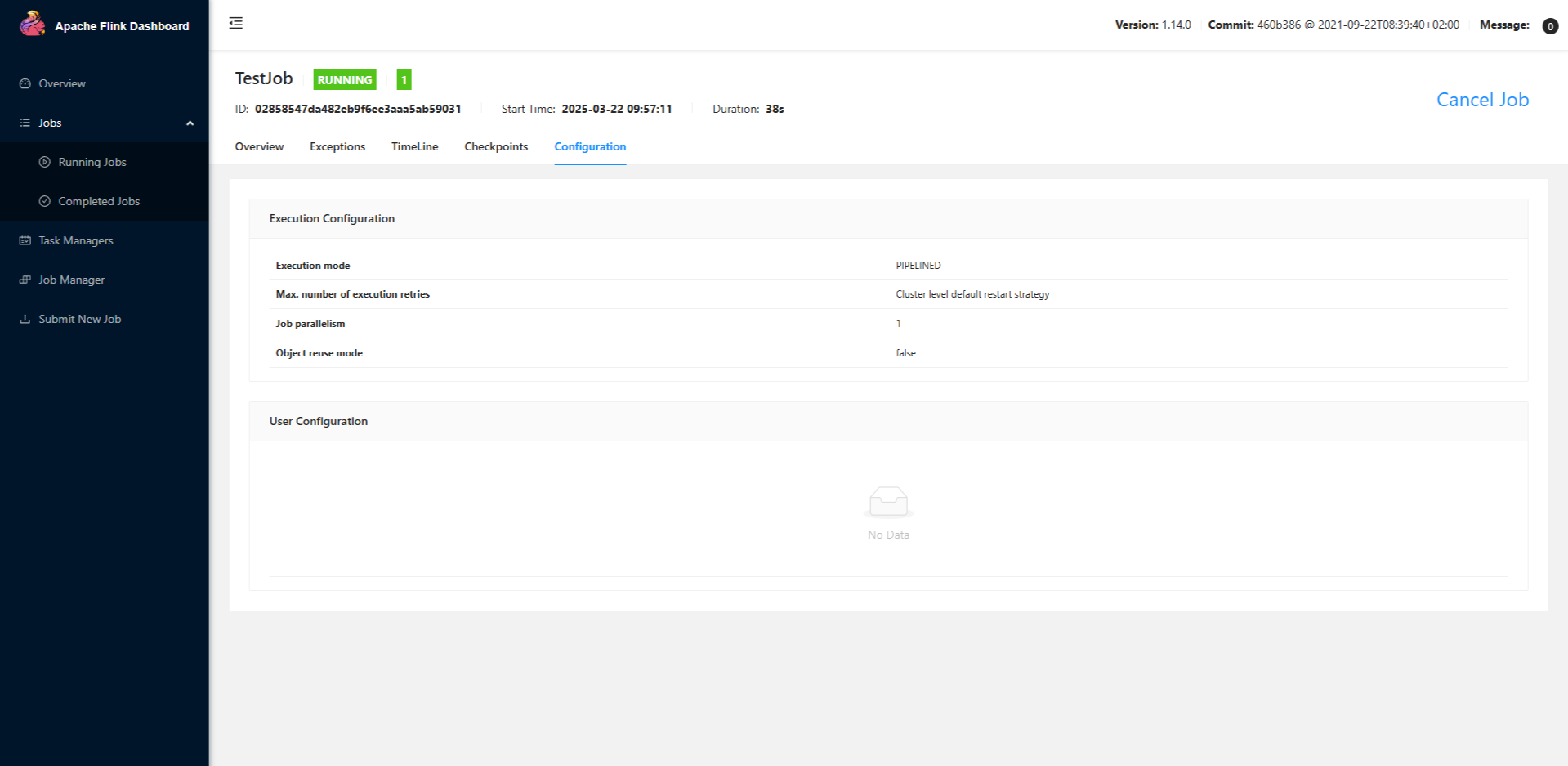
・並列度1の結果
・並列度2の結果
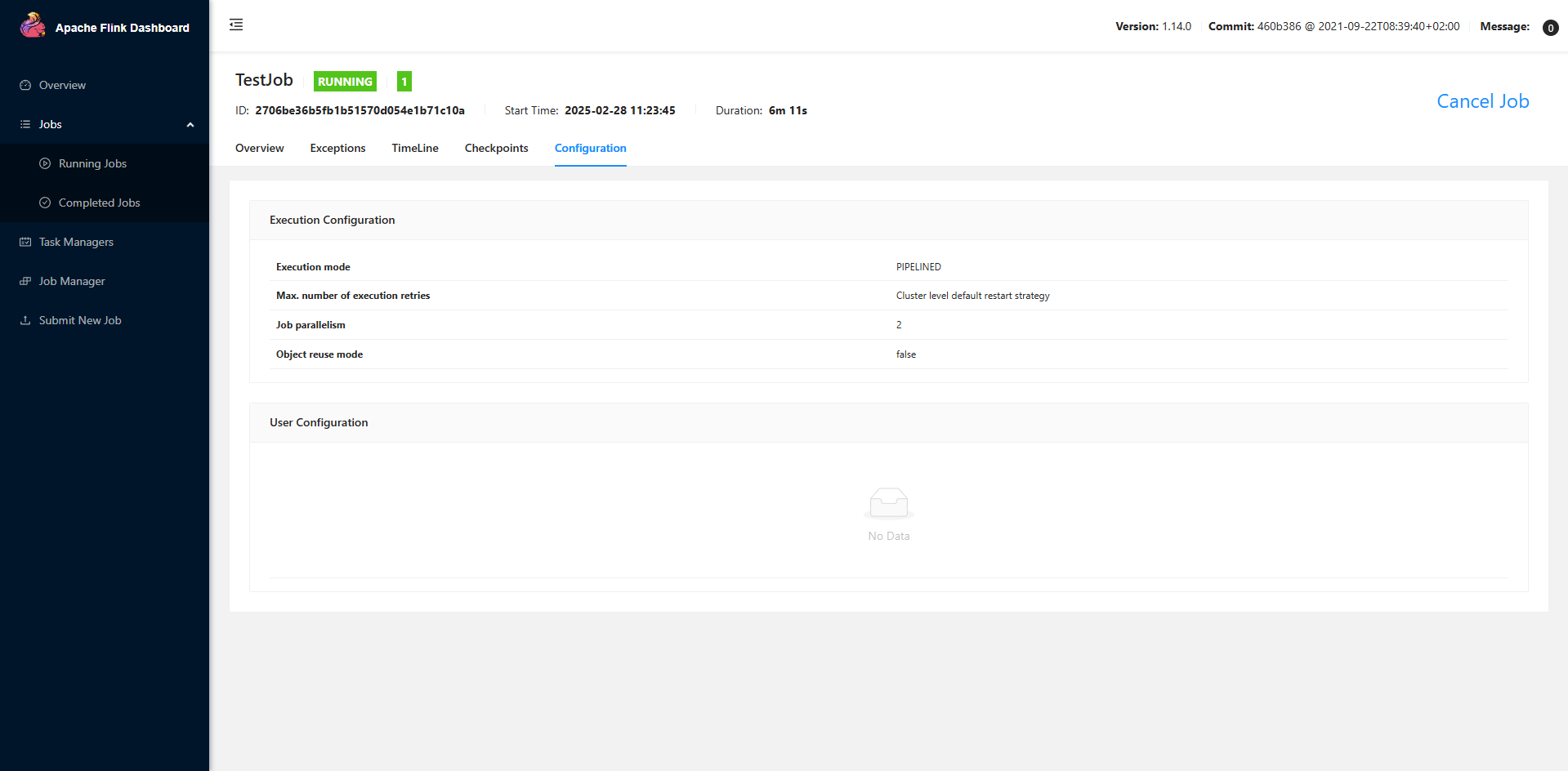
以上のJob Parallelismを確認するとそれぞれ1と2になっており、Beamにおける並列度設定はClient Levelつまり実行されるジョブに対して適用されることが分かったかと思います。
終わりに
ここまで、お読みいただきありがとうございました。
私が調べた限りでは公式の情報でも詳細な記載がなかったため、助けになればと思います。
今後もバックエンドをメインに記事を発信していきます。
▼カジュアル面談実施中!
カジュアル面談では、会社の雰囲気や仕事内容についてざっくばらんにお話ししています。
履歴書は不要、服装自由、原則オンラインです。興味を持っていただけた方は、
ぜひ以下からお申し込みください。
皆さんにお会いできることをサクラグメンバー一同、心より楽しみにしております!
カジュアル面談応募フォームABOUT ME
